Introducing onepot Designer and onepot C1 (Preview)
At onepot, our primary aim is to close the DMTA (design, make, test, analyze) loop. Historically, the “make” step has been the bottleneck, which is why do synthesis: speeding it up makes the whole cycle faster, which means drugs get to trial and to patients earlier. However, in our work, we have noticed a new class of problems: generative models.
There are a few places where generative models are especially useful in small-molecule drug discovery. These include hit exploration, hit-to-lead, and lead optimization: given a molecule, generate similar molecules (either in terms of structure, warhead, or chromophore). Another approach is one-shot drug design: bypassing traditional methods by directly generating drugs that bind to specific targets. Both of these approaches suffer from the same issue: synthesis is fickle. A small change to an easy-to-synthesize compound can produce a molecule that is incredibly hard to make; in general, generative models without good synthesizability priors can produce molecules that will never exist. To get around this, generative models need to be synthesis-aware.
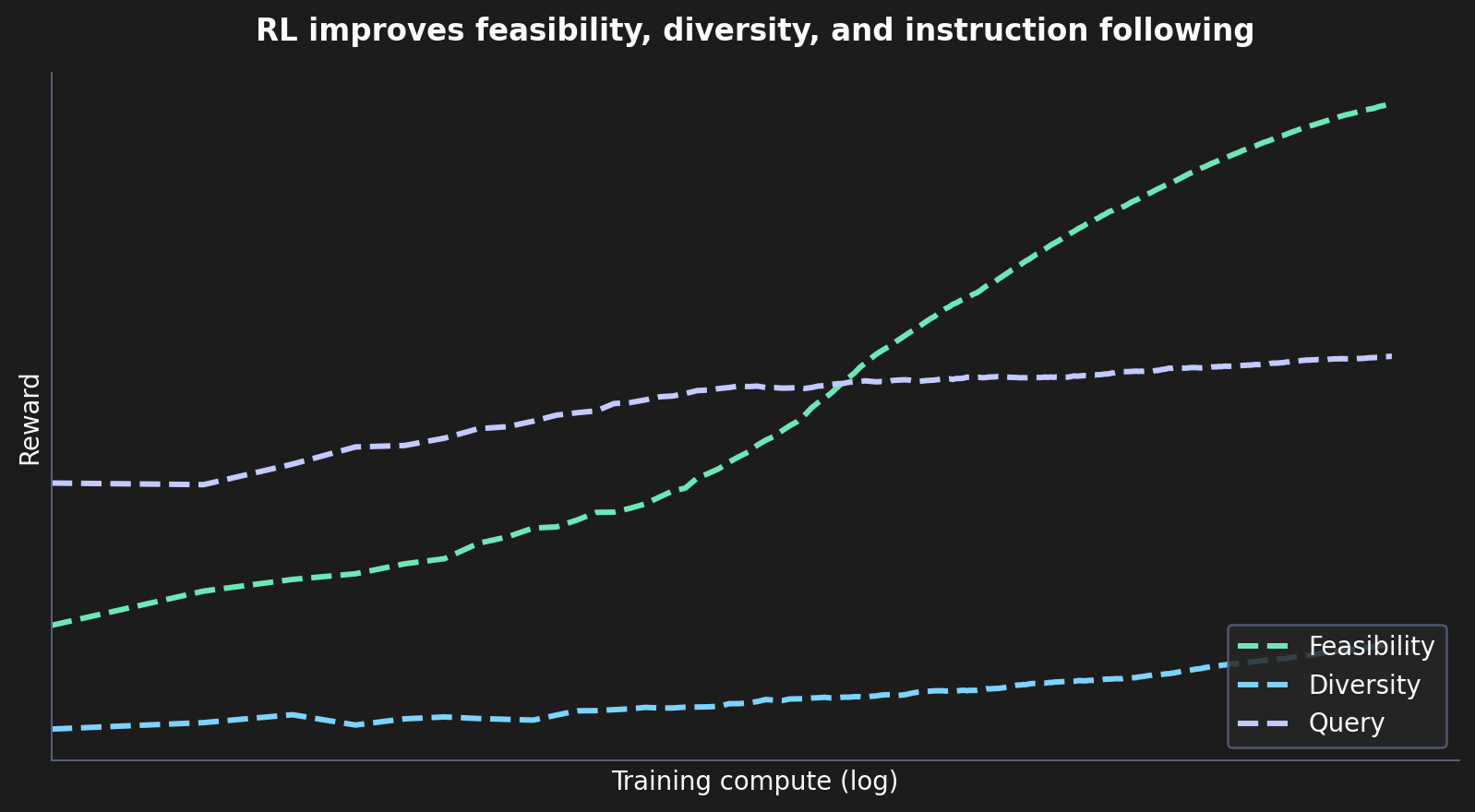
Recent work (SynFormer, PrexSyn, ReaSyn) has shown that it is possible to train such models. Building on said work, we trained onepot C1 (Preview), a 1.2B-parameter model trained on top of CORE v1.1, our space of synthesizable compounds. The model can be conditioned on a reference molecule, specific substructures to preserve, and windows on molecular properties (e.g. MW between 300 and 450). C1 (Preview) also validates our Reinforcement Learning (RL) pipeline, which improves the model along three dimensions:
- Feasibility, generated molecules come with synthesis routes that are likely to work in the lab.
- Diversity, structural and scaffold diversity of generations.
- Instruction following, how closely the model honors the constraints you give it.
All three improve as RL training proceeds:
Custom Models
Our Reinforcement Learning pipeline allows us to post-train onepot C1 to improve any set of metrics. This means that we can adapt C1 to the filters, chemistry, and models your team already trusts: your internal assay context, project-specific property windows, liability rules, preferred chemistries, available inventory, and internal ML models that can condition generation. We are happy to work with your team on custom versions; reach us at hello@onepot.ai.
Target context, internal results, and biological priorities.
Property windows, liabilities, alerts, and project rules.
Preferred reactions, inventory, and building-block access.
Internal ML models that can become conditioning signals.
We also introduced onepot designer, a new platform for using these models, primarily around hit exploration and lead optimization. We plan on releasing more about these models in the future, and welcome your feedback on model improvements.
Want to talk through how this fits into your discovery workflow? Reach out to hello@onepot.ai .